


Overfitting and Underfitting are two crucial concepts in machine learning and are the prevalent causes for the poor performance of a machine learning model. In this blog, I will attempt to explain these two terms in a non-technical manner in order to make it easier to understand.
The main goal of every machine learning model is to be able to learn from data and make accurate predictions when it sees new data. How well it makes the predictions depends on the quality of the data, and what kind of model is used for training. In order to check the performance of the model, we check for overfitting or/and underfitting for the model.
Usually we split our dataset into two categories: one portion is used for training the model, which is known as training data, and the other part is used for testing the model to see if it is making accurate predictions, known as test data.
A Real World Example To Understand Overfitting and Underfitting
Now let's try to visualize how underfitting and overfitting work by taking a real-world example.
Think about a class that includes pupils of three types: A, B, and C. Let's imagine that student A resembles a learner who dislikes paying attention to lectures since he is never interested in the material being covered in class. Student B is a very competitive learner who adheres fervently to rote learning. He doesn't care about how to solve an issue; all he cares about is receiving the best scores possible. The ideal student C, who prioritizes conceptual understanding and problem-solving methodology, rounds out the group.
The following were the scores of the three students in a class test: A, who had no prior knowledge, simply guessed every response, scoring about 50% on the test. B, who had the answers to every question memorized, scored roughly 98%. C used the problem-solving strategy he had learned in class to achieve an estimated score of 92%.
Now consider what happens during final exams, when students are confronted with questions they have never seen before in class. In the case of student A, his score remained essentially unchanged because he still correctly answered 50% of the questions at random. In the case of student B, his score fell dramatically. This is because he simply memorized all of the problems taught in class without understanding the key concepts. In the case of student C, the score also remained relatively constant for the most part. This is because he concentrated on learning the problem-solving approach and was thus able to apply what he had learned to solve the unknown questions.
How Does This Relate To Underfitting and Overfitting in Machine Learning?
Let's work on connecting the example above to better understand the two types of fittings.
To begin, the classwork and class test correspond to, respectively, the training data and the prediction over the training data itself. On the other hand, the semester exam represents the test set from our data which we keep aside for testing (or unseen data in a real-world machine learning project).
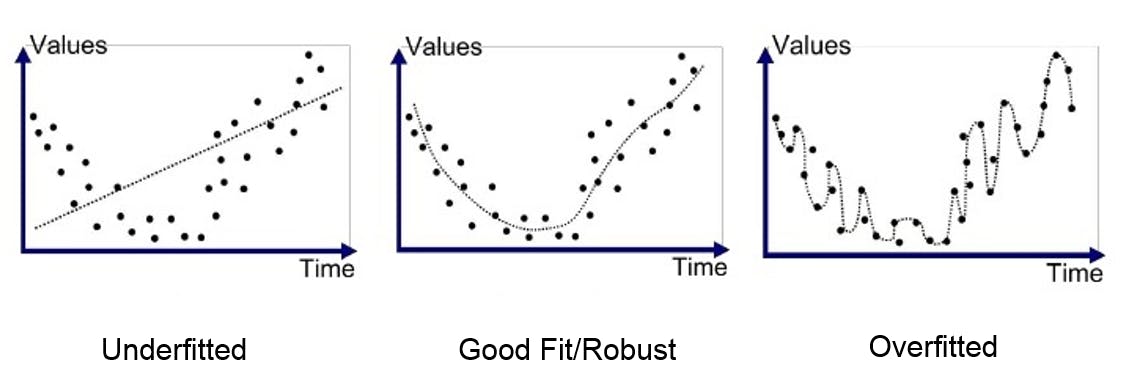
When the model we use for training tries to learn every point from the training data, it ends up confusing the noise in the data as a pattern, and due to this, it is not able to generalize well when it encounters new data from the test set.
This situation where a model performs exceptionally well on the training data but significantly worse on the test data is known as overfitting. You can think of it as it’s good at answering questions it’s already been asked, but when you ask something out of the box the model fails.
Decision trees are the most prone to overfitting as specificity increases as we go deeper into the tree, leading to a smaller number of possibilities that meet the previous assumptions.
On the other hand, if a model performs poorly across the test data as well as the training data, we infer that the model is underfitting
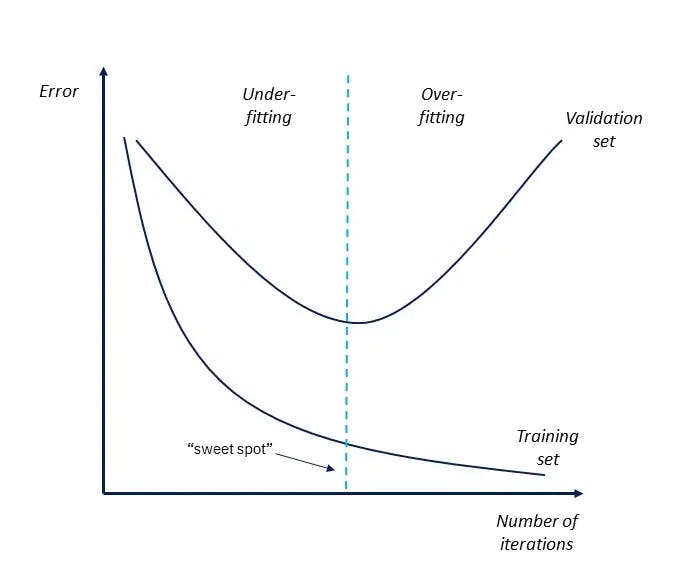
The sweet spot lies somewhere in between, which is called generalization. This is where the model performs well on both training data and new data not seen during the training process.
We shall see how to deal with either should they occur while training our model in a separate article.
That's a wrap for now! If you enjoyed reading, do share what you learned from it on your socials! Thank you for reading!